Key features
Table of contents
- Support for partitioned tables
- BRIN index on the ordering column
- Tags as an array of int
- Minor PostgreSQL optimizations
Support for partitioned tables
When you have big volumes of data and they keep growing, appending events to the journal becomes more expensive - indexes are growing together with tables.
Postgres allows you to split your data between smaller tables (logical partitions) and attach new partitions on demand. Partitioning also applies to indexes, so instead of a one huge B-Tree you can have a number of capped tables with smaller indexes.
Currently, plugin supports two variants of the journal table schema:
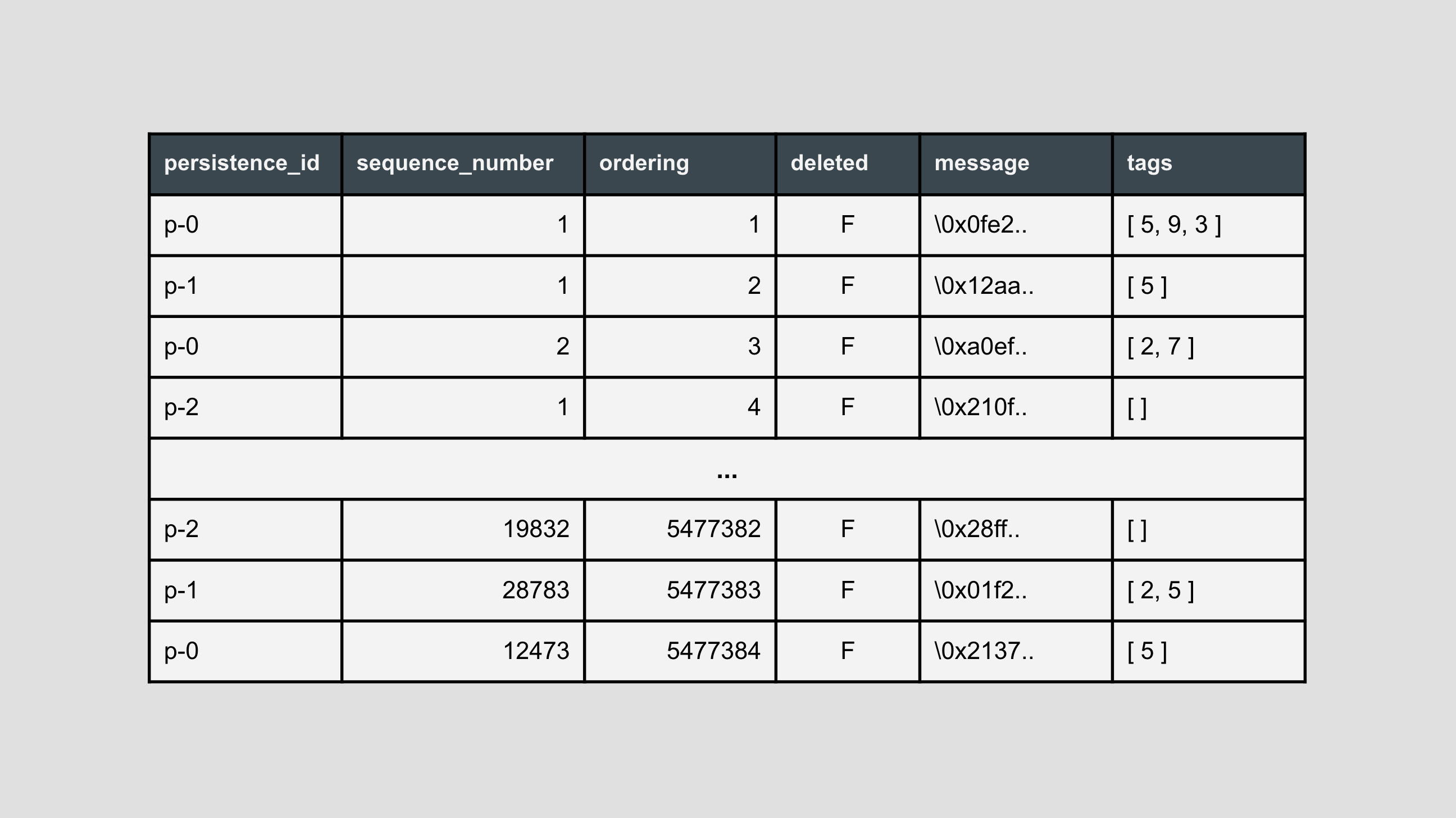
Flat journal
A single table, similar to what the JDBC plugin provides. All events are appended to the table. Schema can be found here.
This is the default schema.
Journal partitioned by ordering (offset) values
A journal partitioned by ordering (offset) values - this schema fits scenarios with a huge or unbounded number of unique persistence units. Because ordering (offset) is used as a partition key, we can leverage partition pruning while reading from the journal, thus gaining better performance. You can find the schema here. 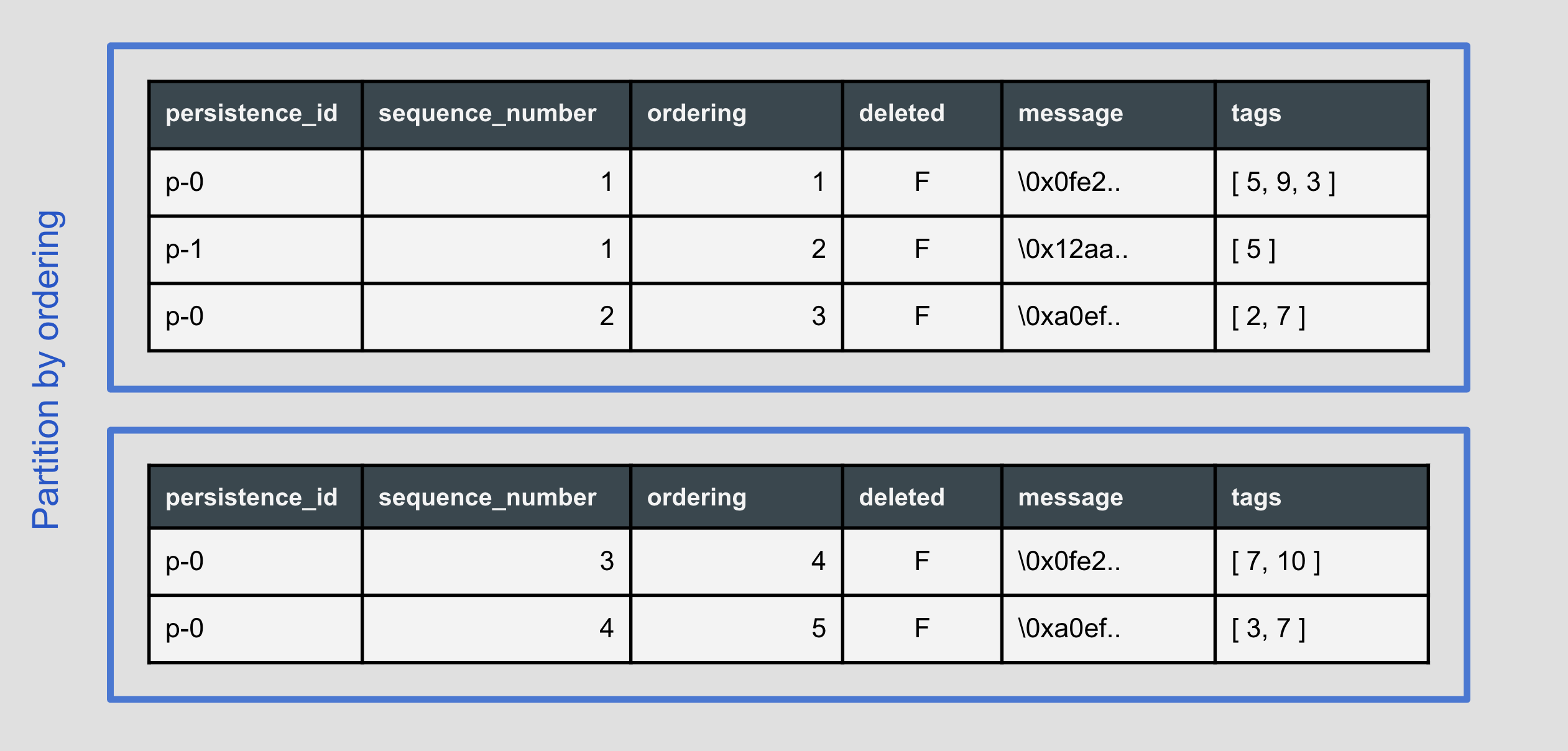
Journal with nested partitions
A journal partitioned by persistenceId and sequenceNumber - this version allows you to shard your events by the persistenceId. Additionally, each of the shards is split by sequenceNumber range to cap the indexes. You can find the schema here. 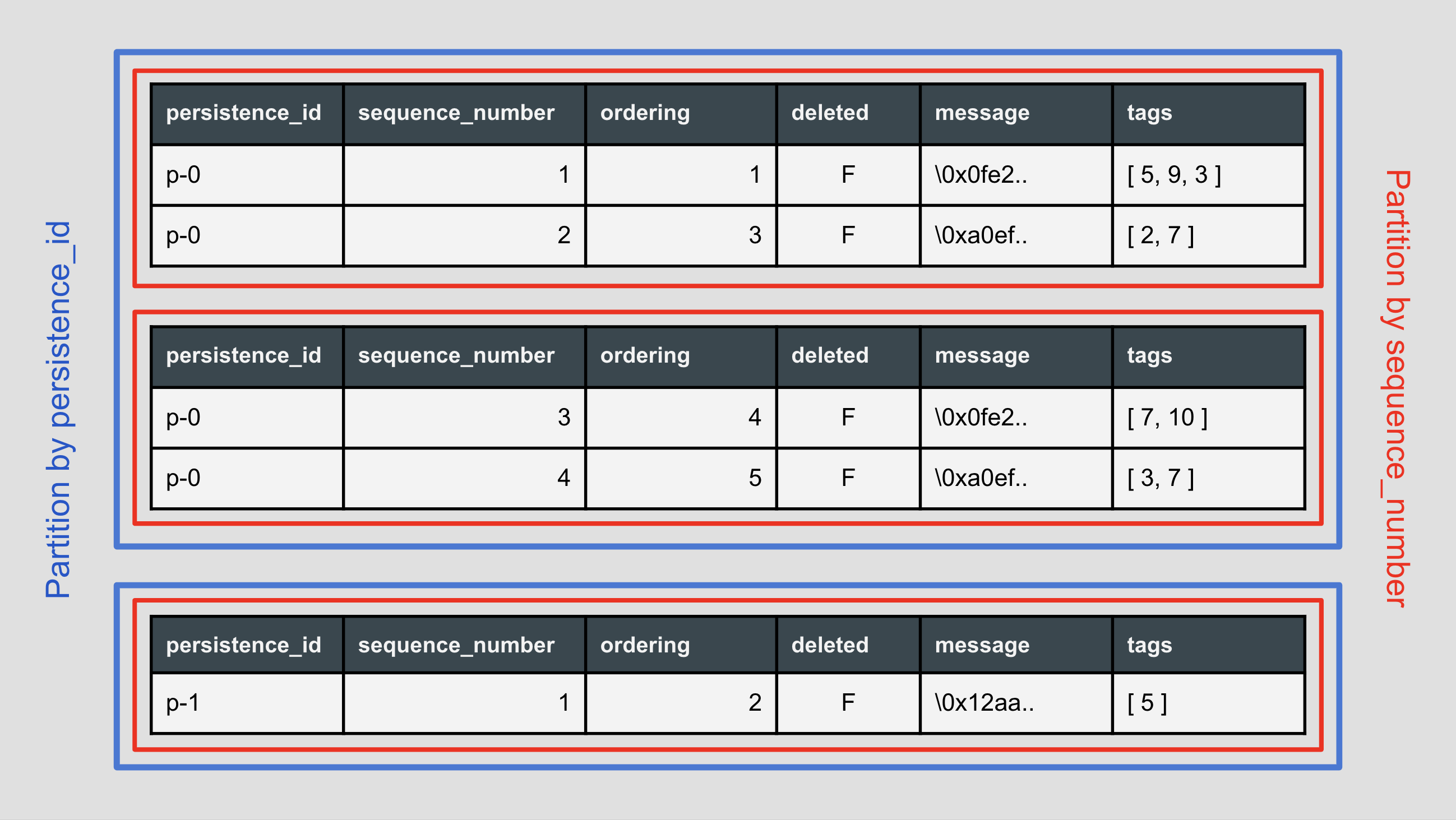
This variant is aimed for services that have a finite and/or small number of unique persistence aggregates, but each of them has a big journal.
Detaching unused partitions
One of the advantages for this variant is that you can detach, dump and remove unused partition (for example - when snapshot has been created) and release the memory (each partition has its own index) and disk space.
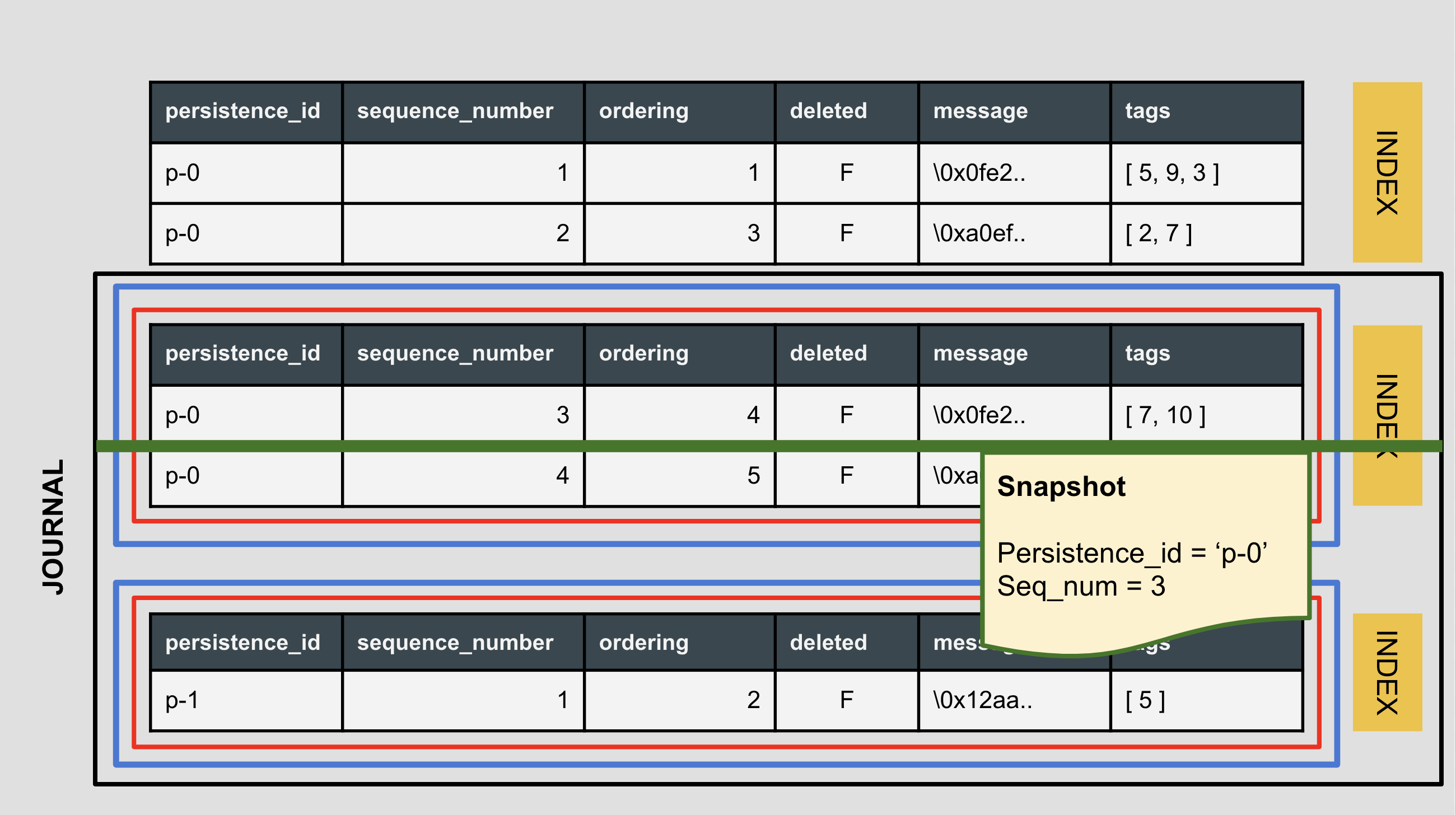
The process is simple and can be automated using this script. It’s also frictionless - once you detach and remove the unused partition you do not have to reindex the table (which often acquires a lock on the table).
Partition pruning
Another plus point is the ability to perform partition pruning. This means that query planner will examine the definition of each partition and prove that the partition need not be scanned because it could not contain any rows meeting the query’s WHERE clause. When the planner can prove this, it excludes (prunes) the partition from the query plan.
BRIN index on the ordering column
This plugin has been re-designed in terms of handling very large journals. The original plugin (akka-persistence-jdbc) uses B-Tree indexes on three columns: ordering, persistence_id and sequence_number. They are great in terms of the query performance and guarding column(s) data uniqueness, but they require relatively a lot of memory.
Wherever it makes sense, we decided to use more lightweight BRIN indexes.
Journal partitioned by ordering column still uses B-Tree index since partition keys has to be included in primary key which must be unique. Unfortunately BRIN indices cannot guard uniqueness.
Tags as an array of int
Akka-persistence-jdbc stores all tags in a single column as String separated by an arbitrary separator (by default it’s a comma character).
This solution is quite portable, but not perfect. Queries rely on the LIKE ‘%tag_name%’ condition and some additional work needs to be done in order to filter out tags that don’t fully match the input tag_name (imagine a case when you have the following tags: healthy, unhealthy and neutral and want to find all events tagged with healthy. The query will return events tagged with both, healthy and unhealthy tags).
Postgres allows columns of a table to be defined as variable-length arrays. By mapping event tag names into unique numeric identifiers we could leverage intarray extension, which in some circumstances can improve query performance and reduce query costs up to 10x.
Minor PostgreSQL optimizations
Beside the aforementioned major changes we did some minor optimizations, like changing the column ordering for more efficient space utilization.